
IQR 개념
![[파이썬] 데이터 이상치 찾기 IQR 확인](https://blog.kakaocdn.net/dn/A9ylB/btsAzbFl1go/1G2TSTXuDuWNG1AKXmiSI0/img.png "[파이썬] 데이터 이상치 찾기 IQR 확인")
핵심 키워드
- IQR = Q3 – Q1
- 기준은 중앙치
- Q1 = 25% 지점
- Q3 = 75% 지점
- 이상치의 범위
- Q1-1.5*IQR 이하
- Q1+1.5*IQR 이상
IQR은 사분위수만 이해하면 어렵지 않습니다. 사분위수는 전체 데이터를 25%씩 4등분한 것을 말합니다.
| Q1 | 25% |
| Q2 | 50% |
| Q3 | 75% |
| Q4 | 100% |
이중 25%~75%의 범위가 Q1~Q3에 속합니다.
Q3-Q1을 하면 75%해당하는 값에서 Q1에 해당하는 값을 빼게 되는데, 이게 기준점이 되어 데이터의 50%에 속하는 범위의 특정 값을 말하게 됩니다.
왜 그런지에 대해서는 데이터를 정리하는 많은 방법 중 이러한 방법이 있다는 정도로만 기억하시면 좋습니다.
중앙치를 기준으로 데이터의 분포 확률과 이상치를 찾는 방법 중 IQR이 있고
이 IQR은 3분위수와 1분위수로 계산하여 특정 값을 뽑아 낸다고 보시면 됩니다.
여기서 중요한 것은 Q1-IQR*1.5, Q3+IQR*1.5 입니다.
앞서 IQR 내의 데이터는 정상 범주를 뜻하는 값이 될 것입니다.
이 Q1과 Q2를 벗어나는 데이터 중 IQR(정상값으로 여겨지는 값)의 1.5배한 값을 이상치라고 보는 것입니다.
더 자세히 알기 ( 다음 내용은 pass해도 좋습니다)
IQR-1.5는 IQR (Interquartile Range)의 1.5배를 의미합니다. IQR은 데이터의 중간 50% 범위를 나타내는 통계적 측도로, 데이터의 상위 25%와 하위 25% 사이의 범위를 말합니다. 일반적으로 이상치(outlier)를 찾는 데 사용되는 상자그림(box plot)에서 이상치를 판별하는 기준으로 활용됩니다. IQR-1.5를 사용하면, 이상치로 간주되는 범위를 정의할 수 있습니다. 이상치를 판별하는 방법은 다음과 같습니다: 1. 데이터의 1사분위수(Q1)와 3사분위수(Q3)를 계산합니다. 2. IQR = Q3 – Q1을 계산합니다. 3. IQR-1.5를 계산하여 하위 경계(lower bound)와 상위 경계(upper bound)를 구합니다. 4. 데이터에서 하위 경계보다 작거나 상위 경계보다 큰 값들을 이상치로 간주합니다. 즉, IQR-1.5를 사용하여 하위 경계보다 작거나 상위 경계보다 큰 값들을 이상치로 정의하는 것입니다. 이상치는 데이터의 분포에서 크게 벗어난 값으로 간주되며, 특이한 혹은 잘못된 데이터 포인트일 수 있습니다. IQR-1.5를 사용하여 이상치를 판별하는 것은 일반적인 방법 중 하나이며, 특정 상황이나 분석 목적에 따라 다른 기준을 사용할 수도 있습니다.
데이터 불러오기
먼저 pandas를 불러와야합니다.
import를 사용하여 pandas를 불러오기import pandas as pd import numpy as np df = pd.read_csv(‘../input/titanic/train.csv’) * 여기서 데이터 경로는 현재 자신이 저장한 곳을 적으면 됩니다.
import pandas as pd
import numpy as np
df = pd.read_csv('../input/titanic/train.csv')탐색적 분석
# 간단한 탐색적 데이터 분석 (EDA) print(df.head) # 반드시 데이터프레이밍명.read print(df.shape) # 반드시 데이터프레이밍명.shape print(df.isnull().df.sum()) # df.isnull() 결측값의 갯수, df.sum() 합산
print(df.shape)
print(df.head)
print(df.isnull().sum())
shape은 간단하게 데이터프레임의 크기를 보여줍니다.
데이터셋 크기: 891 행 × 12 열

head는 데이터의 상위 5개씩 보여주는 역할을 합니다.
데이터셋 구성:
- ‘PassengerId’: 각 승객의 고유 식별자
- ‘Survived’: 생존 여부 (0: 사망, 1: 생존)
- ‘Pclass’: 승객의 객실 등급 (1, 2, 3)
- ‘Name’: 승객의 이름
- ‘Sex’: 승객의 성별 (male 또는 female)
- ‘Age’: 승객의 나이
- ‘SibSp’: 함께 탑승한 형제자매 또는 배우자의 수
- ‘Parch’: 함께 탑승한 부모 또는 자녀의 수
- ‘Ticket’: 티켓 번호
- ‘Fare’: 지불한 운임
- ‘Cabin’: 객실 번호
- ‘Embarked’: 탑승 항구 (C, Q, S)

이 코드는 각 열에 대한 결측값의 개수를 계산하고 출력합니다.
결측값:
- ‘Age’ 열에는 177개의 결측값이 있습니다.
- ‘Cabin’ 열에는 687개의 결측값이 있습니다.
- ‘Embarked’ 열에는 2개의 결측값이 있습니다.
IQR 분석
IQR은 사분위수 중 1분위와 3분위수로 계산합니다.
# IQR 구하기
Q1 = np.percentile(df['Fare'], 25)
Q3 = np.percentile(df['Fare'], 75)
IQR = Q3 - Q1
minimum=Q1-1.5*IQR
maximum=Q3+1.5*IQR
print(minimum)
print(maximum)이렇게 계산한 IQRQ1 = np.percentile(df[‘Fare’], 25) Q3 = np.percentile(df[‘Fare’], 75) IQR = Q3 – Q1 minimum=Q1-1.5*IQR maximum=Q3+1.5*IQR print(minimum) print(maximum)
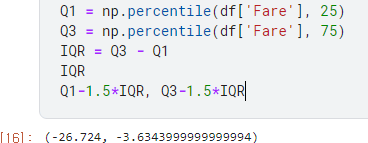
우리가 계산하고자 하는 이상치를 구하기 위한 기준 값을 뽑아 낸 것입니다.
이상치 갯수 구하기
실제 분석에서 전체 이상치를 구하는 것이 흔히 있을 수 있으며, 현재 방법은 그리 효율적이지 않을 수 있습니다.
out_low = df[df['Fare'] < minimum]
out_high = df[df['Fare'] > maximum]
print(out_low.shape[0])
print(out_high.shape[0])
print(out_high.shape[0]+out_low.shape[0])다만, 빅데이터 분석기사나 여러 방법을 알아두기에는 나쁘지 않습니다.out_low = df[df[‘Fare’] < minimum] out_high = df[df[‘Fare’] > maximum] print(out_low.shape[0]) # 갯수를 확인할때는 .shapep[0]을 쓸 것. print(out_high.shape[0]) # 혹은 len()을 활용할 수도 있음
